紫微算命面壁小钢炮4.0发布:性能比肩 Qwen-3-8B,极限220倍提速
紫微(🚇)算命 新浪科技讯 6月10日下午消息,近日,面壁智能第四代“面壁小钢(🖋)炮(🍺)” MiniCPM4.0 端侧模型(代号“前进四”)发布。据悉,第四代小钢炮拥有 8B 、0.5B两种(🥣)参数规模,实现了同级最佳的模型性能。可让长文本、深思考在端侧真正跑起来,实现220倍极(🙂)限加速。
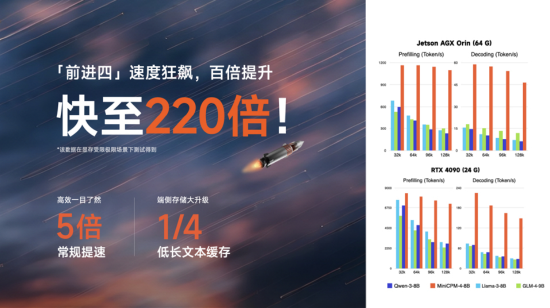
紫微(🕤)算命 其中,MiniCPM 4.0-8B 模型为稀疏注意力模型,在MMLU、CEval、MATH500、HumanEval等基准测试中,以仅22%的训练开销,性能比肩 Qwen-3-8B、超越Gemma-3-12B。MiniCPM 4.0-0.5B在性能上,也较更大的Qwen-3-0.6B、Llama 3.2实现仅2.7%的训练开销,一半参数性能翻倍,并实现了最快 (🧣)600 Token/s的极速推理速度。
紫微算命 相(🏟)较于Qwen-3-8B、Llama-3-8B、GLM-4-9B等同等参数规模端侧模型,实现了长文本推理速度5倍常规加速以及最高 220倍加速(显存受限极限场景下测出),让端侧模型长(👐)文本推理“快(🎼)如闪电”。面壁智能联合创始(💼)人兼(❎)首席科学家刘知远在与新浪科技沟通中(🌡)表示,“最高220倍加(👲)速,其实是建立在我们模型架构、数据治理、软硬件结合、训练等方面全栈创新优化成果之上的。”
紫微算命 刘知远指出,220倍的加速看上去比较夸张,但本身其实存在一个特殊性——由于MiniCPM4.0 在处理更长序列的数据时,可以更好地去处理Transformer架构带来的内存爆炸问题,避免了长序列数据处理带来的内存占用倍增,而同尺寸的Qwen-3-8B、Llama-3-8B等模(🍛)型并未就此进行优化,因此MiniCPM4.0有了突出的表现。
紫微算命 据悉,MiniCPM 4.0 模(👇)型采用的InfLLMv2稀疏注意力架构改变了(🚥)传统 Transformer 模型的相关性计算方式,有效摆(🌔)脱了逐字重复计算的低效,将稀疏度从行(🚷)业普遍的40%-50%,降至(🌨)极致的5%,注意力层仅需1/10的计算量即可完成长文本计算。且对算子底层重写,进一步加速提升,并使得对文本相关性精准性大大提升。
值得一提的是,DeepSeek 使用的长文本处理架(🈚)构NSA(Native Sparse Attention)也引用并采用了与InfLLM相同的分块注意力计算思路,但其对于短文本的推理较慢,InfLLMv2则很好地解决了NSA在短文本推理上的短板。
在缓存消耗上,MiniCPM 4.0-8B在 128K 长文本场景下相较于Qwen3-8B仅需 1/4 的缓存存储空间。在速度、性能飙升的同时,又做到了模型极致压缩,让端侧算力不再(🚵)有压力。
紫(🎄)微算命 据悉,基于 8B 版本,面壁智能已微调出两个特(⤵)定能力模(🍅)型,分别可以用作 MCP Client 和纯端侧性能比肩Deep Research的研究报告神器MiniCPM4-Surve。截至目前,面壁小钢炮 MiniCPM 系列全平台下载量累计破1000万。(文猛)
相关链接:
- 中国航发:“太行 7”燃气轮机累计运行突破 20000 小时
- 三大科创平台揭牌2025年武汉市青山区科技创新大会成功举办
- 2025“桃李新苗”少儿舞蹈展演--童心舞动未来,天桥剧场绽放艺术之光
- 端午小长假深圳铁路预计发送旅客169.5万人次
- vivo X Fold5 折叠屏手机通过 3C 认证,支持 90W 快充
- 真奶真浓真好吃:八喜雪芭 / 珍品等冰淇淋 5.5 元季前狂促(商超 10 元)
- 面壁智能与易来联合发布 Yeelight Pro S 系列智慧屏,行业首款纯端侧 AI 家居中枢
- 推荐北京高考结束,有家长捧烤串迎接考生:孩子喜欢吃,也寓意“考好了”
- 小米 YU7 预发布:全系 800V / 中大型纯电 SUV 续航第一,7 月上市,“不可能”19.9 万元
- 北京路县故城遗址公园和博物馆对公众试运行开放
相关新闻
- 紫微算命山西沁源山火明火已灭 救援力量纵深清理火场详细阅读

中新网长治6月14日电 (记者 李庭耀)记者14日从山西省长治市沁源县沁河镇山火救援现场获悉,火场于13日下午开始断续降雨,救援力量抓住时机继续扑...
2025-06-1662
- 紫微算命外交部:加沙冲突不能再延宕,人道灾难不能再继续详细阅读

中新网北京6月13日电 (记者 李京泽 曾玥)中国外交部发言人林剑13日主持例行记者会。外交部发言人林剑。薛伟 摄 有记者提...
2025-06-1677
- 紫微算命以军F-35战机被击落?伊朗媒体公布照片详细阅读

图源:伊朗伊斯兰共和国官方账号14日在社交平台X上公布被击落的以色列F-35战机残骸照。 伊朗塔斯尼姆通讯社14日在社交媒体公布一架被伊...
2025-06-16106
- 紫微算命博泰车联网应宜伦:应积极拥抱人工智能,伦理责任先放后详细阅读

专题:2025轩辕汽车蓝皮书论坛 2025第十七届轩辕汽车蓝皮书论坛于2025年6月13日-15日在广州举行。 博泰车联网创始人、董事长应宜伦...
2025-06-15114
- 紫微算命高效、精量、协同 三个关键词解码“三夏”科技范儿详细阅读
AI解锁丰收密码丨高效、精量、协同 三个关键词解码“三夏”科技范儿 从5月中旬西南麦区大面积机收开始,到今天,全国冬小麦收获已进入全面收尾...
2025-06-15127
- 紫微算命闯关港股IPO,频繁融资的亿纬锂能有多缺钱?详细阅读

炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会! 来源:尺度商业 2025年,港股新股市场非常火热,多家A股公司相...
2025-06-15161
- 紫微算命A股重大调整,明日生效详细阅读

A股系列指数调样,明日生效!根据此前消息,6月16日为A股系列指数定期例行调整的生效日。这次调样的指数包括上证50、上证180、上证380、科创50...
2025-06-15171
- 紫微算命印度客机坠毁机场暂停运营详细阅读
据印度媒体援引艾哈迈达巴德机场发言人消息,受坠机事件影响,艾哈迈达巴德机场目前暂停运营。所有航班暂停运行,直至另行通知。 总台记者获悉,一...
2025-06-15185